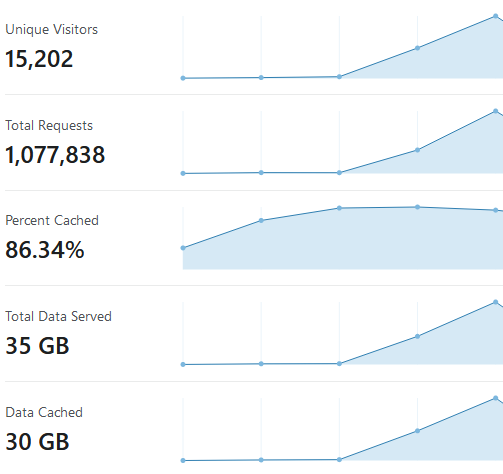
This post is written for an engineering audience. If you're interested in programming & DevOps, this is the article for you!
When we launched TEAMS.gg to our early access mailing list in August, we were thinking we'd get perhaps a couple of hundred signups over "Launch week". We never expected the CS:GO community would bite so hard! We've now got thousands of people using TEAMS.gg to find their perfect teammates.
I'd structured our platform to take maybe 500-1000 people on launch. That's not what we ended up with (think an extra order of magnitude), so our "proper" launch day wasn't entirely without incident.
The architecture of TEAMS.gg
Before we go into the specifics of why I had to stay up most of launch night, fixing and nudging and migrating, it's probably good to give a bit of a primer on the main "components" that TEAMS.gg is made of.
- Rails application
- This is the main web application that runs the site. When you access https://teams.gg, you're communicating with this app.
- Rails worker
- We use resque to process background jobs, used for things like sending emails and communicating with the FACEIT API.
- Clock process
- We use clockwork as a scheduler to run certain jobs - like sending reminder emails or expiring listings - on a schedule.
- Matching engine
- Our ranking and matching engine is written in Golang. This is our secret sauce, so don't be surprised if I don't go into too much detail about its internals ;)
- Datastores
- PostgreSQL, the main application database where your data is stored safely
- Redis, an in-memory key-value store used by our clock and worker processes.
All of these processes were (more on this later..) built into docker containers, using our internal Gitlab CI server, and run on virtual machines using compose. Some of you are probably starting to see some of the pitfalls I was about to experience.
How did our stack change throughout the night?
Core stuff that didn't change:
- Cloudflare as a CDN and DDoS attack prevention layer
- HAproxy based load balancer for web traffic
At the start:
teamsgg-apps-14gb ram/2 cpu, ran everythingteamsgg-datastores1gb ram/1 cpu, redis and postgres
At the end:
teamsgg-web-1(2gb/2cpu, web process)teamsgg-web-2(2gb/2cpu, web process)teamsgg-master(4gb/2cpu, worker and clock processes)teamsgg-datastores(8gb/4cpu, redis only – this is oversized now for redis alone – but scaling machines down is harder than scaling them up)- Managed PostgreSQL database
How did it go?
17:44 Boundary issues with faceit ELOs

Always check your boundaries. Someone signed up with a faceit elo of 2001, which broke not just their experience, but everyone elses who saw them on discover.
For reference, here's the faceit boundaries:
FACEIT_BOUNDARIES = [
{level: 1, min: 0, max: 800},
{level: 2, min: 801, max: 950},
{level: 3, min: 951, max: 1100},
{level: 4, min: 1101, max: 1250},
{level: 5, min: 1251, max: 1400},
{level: 6, min: 1401, max: 1550},
{level: 7, min: 1551, max: 1700},
{level: 8, min: 1701, max: 1850},
{level: 9, min: 1851, max: 2000},
{level: 10, min: 2001, max: 9999},
]
Here was the fix:

I decided at that point that a test on this part of our site would be helpful too ;)
22:53 Worker starving web processes
It'll come as no surprise that our matching "secret sauce" is a little more CPU intensive than web requests. The unexpected load on this was starting to "throttle" the web processes, and make everyone's experience of the site worse.
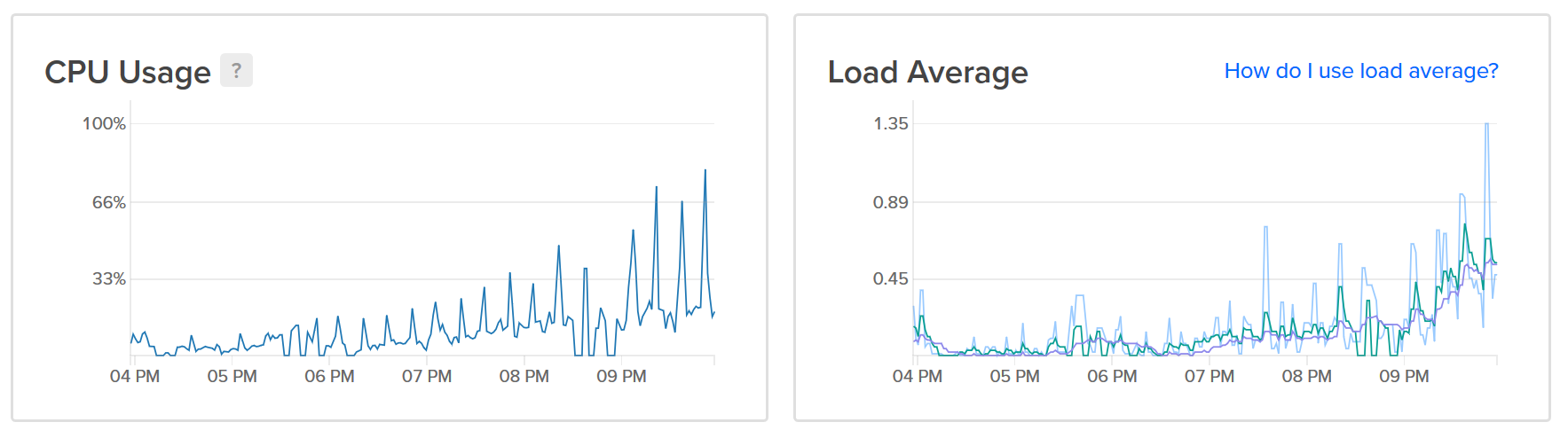
Here, I got lucky. Earlier on that day I'd started to move our configuration of virtual machines into Ansible, so setting up a new web and worker process was as simple as creating a new VM, applying ansible to secure and push the deploy scripts to it, and pulling down the web container to execute.
Then adding it to our load balancer.
That way, it wouldn't matter if we got 20,000+ signups – people could still use the site!
nb: the matching engine has since been made significantly more efficient – think 100x speedup – through some judicious performance profiling!
01:10 – Database memory usage...
One of about fifteen messages that all came in at once:

Ouch. Our database had restarted. It appears some of the larger queries we were running were causing a segfault after a few hours of operation. Not great.
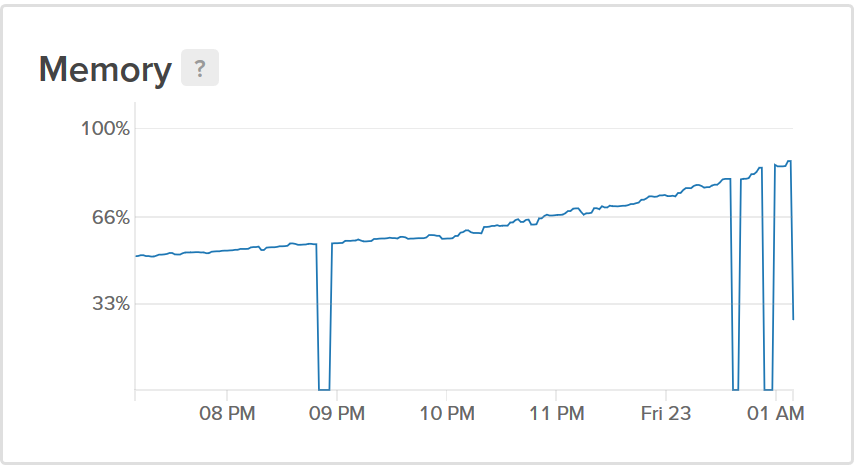
After noticing this leak, I decided not to do anything about this for now, other than grow our database instance to 8gb of RAM – I figured "oh well, it's leaking – I'll fix it in the morning!". Didn't have the brainpower to look at it at 1am!
This would be prescient.
06:10 - Database drops again
I'd tried to get to sleep about an hour before. All of a sudden my phone starts binging and it's this problem again.
I decided that I'd do the fastest, most fraught database migration I'd ever done in my life. I put the site into maintenance mode (by spinning up an nginx instance with a static site...), stopped all the processes, created a database backup (thankfully, we have encrypted backups taken nightly, so triggering a manual one was easy), and then restored it to a new, managed, database.
The site was down for less than 10 minutes!
This didn't stop the issue entirely[1], but it did give us enough headroom so our database would only break every day, instead of every hour.
[1] Turns out, this was two unrelated problems. We had an overly aggressive query that would ask for >20GB of data at a time. This would cause the database engine to crash. Rather than doing a deep dive into Postgres's configuration, I fixed the query that generated such a large ask of data, and introduced intelligent caching downstream in the consumer to reduce how often the query was sent.
This reduced the frequency of crashes, but wasn't the whole story. It was still crashing about once every few days. After going back-and-forth with the provider of our managed database, they gave me a pointer.
"The most common reason for this behavior is that the client is piling up prepared statements on the server and not DEALLOCATE'ing any of them."
Aha, I thought! Our worker uses prepared statements! Perhaps that's it. So I checked, and sure enough, adding a single defer stmt.Close() to the DAO of our worker solved the crashing problem.
08:42 - identify breaking with larger images
And the final fire of launch day – well, launch+1 morning, at this point.

When uploading larger files, our woefully low-RAM web instances would run out of memory while performing an imagemagick identify operation.
Not great, because this breaks the signup flow for the unlucky CS:GO player.
The quickest fix for this was to enable swap on the web process machines; it'll take a far longer time to return a response if you upload a larger image, but at least the process won't fail miserably.
Learnings!
Most of these are things I already knew, it must be said, but this certainly reinforced them in my mind.
Never run your own database in production!
Having to manually investigate segfaults on a database running in docker sucks.
Moving to a managed datastore is more expensive, sure, but gives you so much assurance that someone more intelligent than you is managing this kind of thing. Someone whos day to day job it is to make sure databases run well.
The difference in cost wouldn't be material for a funded startup -- but remember at this stage, it's just the three of us, paying for the infrastructure out of our own pockets. Reducing the overhead matters if we're going to keep TEAMS live for the CS:GO community in the long term.
Of course, it didn't solve our immediate issue, but if we'd started with that? I'd immediately have started looking at my code as the culprit, rather than diving straight to the datastore.
Always separate your web processes from your workers
If you have any kind of CPU-intensive process running, other than web, have it happen on a separate virtual machine.
That way, you can debug it without the stress of also needing a "quick fix" to make your site functional again.
Load balancers rule, ok?
This is systems 101. Don't ever point DNS directly at a machine.
Send your traffic through a load balancer. Always. Even if you only have one machine. That way you're not having to muck about with DNS if you need to add new servers because you're more popular than you expect.
Using modern cloud providers, you can always remove it later if your launch doesn't get traction, and it'll cost you pennies.
This is one I'm happy I did, rather than something I wished I'd done.
Kubernetes would have hurt, not helped
If I was intimately familiar with Kube, and had used it day-to-day in my day job up to this point, this might be different. But I'm not in that space.
I've lost count of the amount of times I tried to set up k8s to run TEAMS.gg. Each time, I got frustrated at complexity I didn't need, and cost we didn't have to incur.
Again, remember we're a 3-person startup, with a single backend co-founder. Me. Managed Kubernetes seems to have a "cost floor" of about $150/month, just for the applications, and involves an entire skillset that I don't have. And it's more important for me to spend time building features than learning infrastructure!
In the end, application scaling wasn't anywhere close to a problem on launch. Once the web process was separated, which was trivial to do by spinning up a new VM and adding it to the load balancer with a few clicks, zero problems with stability or availability.
We have an infrastructure repo containing some docker-compose files, which make use of inheritance, to launch all of the different containers. That's run by a set of bash scripts – deploy.sh – executed on the node when we want to update the containers to a newly built version.
That happened manually on launch (through me – through our jumpbox, sshing in and performing a manual deployment). Now it happens whenever I commit to master, automatically, through a deploy.yml ansible script.
It works. It's not perfect, and as we grow I'll probably look to move to container orchestration – especially as we move beyond a single HTTP-handling application – but for now, it's what we needed to launch.
Use a configuration management tool (like Ansible) to provision your machines
It's easy during the frantic stress of a launch to forget to do common things like secure your infrastructure. Or to remember to check all your processes and SSH daemons are only listening on the private, internal network (and not to the wider internet!).
To be clear, I made neither of those mistakes on launch night – the systems that run TEAMS.gg are as secure as I can make them – but having the configuration management of the VM's sitting within Ansible is one of the things I credit for avoiding that.
I could spin up new web VM's in minutes, correctly and safely. Bonus.
And finally...
Cloudflare is the supreme overlord of all things and I bow down to its superiority. This is taken 8 hours into our launch. Sure, we're not "twitter scale", but it did us alright.